In this assignment I will be evaluating award/grant data from four federal sponsors: The National Science Foundation (NSF), The National Institutes of Health (NIH), The Department of Energy (DOE), and The US Department of Agriculture (USDA).
DATA
1. Department of Agriculture (NIFA) See the data dictionary here Figure 1. This includes agricultural related grants all the way from the early 2000s.
2. Department of Energy (DOE) The data dictionary for this extensive data set can be accessed here Figure 2. This data is not restricted to a particular award recipient.
3. National Institutes of Health (NIH) This data can be obtained from an Application Programming Interface (API). You can access this data’s dictionary here Figure 3. This is quite a large data set with information on awards (related to health sciences) recieved by BSU and U of I between 2013-2024. Of note, this is an example of heirarchal data- some cells appear to have no values in them becuase there are actually multiple variables within those cells.
4. National Science Foundation (NSF) The NSF also has an API, and the following code pulled down awards to the University of Idaho into a data frame called NSFtoUI. See the data dictionary here Figure 4. Briefly, this data set gives information on NSF grants awarded to the University of Idaho from 1975 to current day.
QUESTION 1
Provide a visualization that shows our active awards from each sponsor. I need to see their start date and end date, the amount of the award, and the name of the Principal Investigator. I’m really interested in seeing how far into the future our current portfolio will exist. Are there a bunch of awards about to expire? Are there a bunch that just got funded and will be active for a while? Does this vary across sponsors?
I am going to manipulate and make new data sets for all sponsors. Then I will combine them all and plot a summary figure.
Putting all the active awards from various sponsors together
Question1Visualization
Figure 3. This figure shows U of I PI last names and their active grants they have received as of 2017. The bars are colored by sponsor and the text amount signifies the amount they have received for said award. The USDA data is not included due to a lack of necessary variables. The strengths of this figure is that it displays, rather than over plots, PIs who have multiple awards. Limitations are that this figure only includes grants that have started in 2017 and on.
QUESTION 2
What is the proportional representation of new awards to the UI from these various sources over the past 5 to 10 years? Are there any trends that are encouraging or discouraging?
Putting all the sponsors together
Figure 5. This figure shows the approximate trends of new grants received by the University of Idaho from various sponsors in the last 10 years.
Limitations include that the USDA data set did not have specifications denoting whether the awards were new or continuing, therefore, I was only able to go off the award date for being in the last 10 years and had to make the assumption all were new. This is most likely not the case, so the orange line should be interpreted with caution. In general, the USDA actually seems to be on the decline, which would be concerning given the type of school the University of Idaho is. As for the DOE, it seems we are on the rise during the past couple years. The NSF seems to be steady at the moment. Meanwhile, the NIH data was interesting. Upon updating this document, grants considered “new” a week previously were not considered “new” anymore. Therefore, I just included all grants from the past 10 years. All in all, this is an interesting figure to address general trends within the last decade.
QUESTION 3
How is UI performing with these sponsors when compared to the following peer institutions: Boise State University,Idaho State University,Montana State University,University of Montana, andWashington State University?
Note that “performing” can mean a variety of different things. You must choose your metrics of performance and justify them.
I am going to use the API sources for this question (NIH and NSF) by manipulating the API addresses and then manipulating the data.
Combining NIH and NSF for neighboring schools
Figure 6. This figure shows the award amounts of the active grants of each institution (and their various locations) sponsored by the NIH (coral) and NSF (blue).
I used the measures of active awards and their relative amounts from these sponsors to address how the U of I compares to neighboring institutions. Although not complex, these performance attributes capture important metrics nonetheless.
The limitations of this figure are first and foremost that it only addresses grants from the NIH and NSF, not the USDA and DOE. I chose to do this out of sake for convenience. Also, for the NIH, this time I added the indirect and direct costs to compute the award amount (in Figure 1., I only used direct cost). Further, because of the discrepant data sources, some of the institutions have multiple locations also shown in this figure. Although I could agglomerate the data so each institution has one reference point, I actually think this may be insightful to see how the smaller institutions compare to the larger ones. In general, I could clean this figure up to look a little nicer.
All in all, from this figure, we can see the U of I compares well in the realm of NSF grants. This is not so much the case for the NIH grants.
SUMMARY
In conclusion, this stuff is messy indeed! Throughout my three main visualizations, I found out what active grants the U of I has and how those compare across sponsors. I then expanded that information to compare specific sponsors to various other schools nearby. In general, we need more DOE and NIH work to be done. USDA and NSF are doing well, but we want to get back on the rise again (at least with the USDA).
I realized through this work that, as Barrie has alluded to, it indeed does take a lot of time going through these different data and finding what is similar/comparable and cleaning those aspects of the data in order to put visualizations together. Further, I learned the hard way that LESS IS MORE!
I think it would be interesting to continue to explore and see how the U of I compares to other institutions with the other sponsors, and I wonder how data scientists wrap their heads around all these details!
APPENDIX
Data Dictionary
Attribute
Description
Type
Award Date
Date when award was granted
Ordinal
Grant Number
Unique ID for each grant
Item
Proposal Number
N/A for all
NA
Grant Title
N/A for all
NA
State Name
State of award (all = IDAHO)
Categorical
Grantee Name
Tells who received the grant (all = U of I)
Categorical
Award Dollars
Award amount
Quantitative
Program Name
Name of program grant will be used for (some are N/A)
Categorical
Program Area Name
Name of program (some have N/A)
Categorical
Figure 1: USDAtoUI Data Dictionary
Attribute
Description
Type…3
…4
…5
…6
Type…7
Award Number
ID of award
Item
NA
NA
NA
Ordinal
Title
Title of award
Item
NA
NA
NA
Item
Institution
Organization to whom award was granted. Some are universities, but others are companies and laboratories (many are included, not just U of I)
Item
NA
NA
NA
Ordinal
City
City of that organization (many- not restricted to Moscow)
Item
NA
NA
NA
Ordinal
State
State of that organization (many, not restricted to ID)
Item
NA
NA
NA
Ordinal
Zip Code
Zipcode of that organization
Item
NA
NA
NA
Quantitative
PI
Principle Investigator to whom award was granted
Item
NA
NA
NA
Quantitative
Status
Tells if award is ongoing or not (seems that only active/current awards are included in this data set)
Categorical
NA
NA
NA
Categorical
Action Type
Tells if the award is new or a renewal
Categorical
NA
NA
NA
Item
Org Code
Unique code for the award
Item
NA
NA
NA
Ordinal
SBIR/STTR
Tells if the awards are SBIR (Small Business Innovation Research) or STTR (Small Business Technology Transfer) programs. Neither = N/A
Categorical
NA
NA
NA
Quantitative
Program Office
Tells what DOE program office oversees the award
Categorical
NA
NA
NA
NA
Award Type
Tells type of award (grant, interagency agreement, cooperative agreement)
Categorical
NA
NA
NA
NA
PM
Project Manager (appear to be different people than PI)
Item
NA
NA
NA
NA
Start Date
Award start date
Ordinal
NA
NA
NA
NA
End Date
Award end date
Ordinal
NA
NA
NA
NA
SBIR Phase
If applicable, phase of SBIR
Categorical
NA
NA
NA
NA
Most Recent Award Date
Date of most recent award
Ordinal
NA
NA
NA
NA
Amount Awarded to Date
Money given as of most recent award date
Quantitative
NA
NA
NA
NA
Amount Awarded this FY
Amount awarded this fiscal year
NA
NA
NA
NA
NA
Program Area
What type of program the award will be used towards
Item
NA
NA
NA
NA
Register Number
Unique code for the award
Item
NA
NA
NA
NA
UEI
Unique code for the award
Item
NA
NA
NA
NA
DUNS
Unique code for the award
Item
NA
NA
NA
NA
Institution Type
Type of institution that has received the award
Categorical
NA
NA
NA
NA
Abstract
Abstract of what award is proposed to be used for
Item
NA
NA
NA
NA
Figure 2: DOE Data Dictionary
Attribute
Description
Type
appl id
Unique ID
Item
subproject id
Some awards have subproject unique ID values
Item
fiscal year
Year of award
Ordinal
project num
Project number (seems to be a grouping variable)
Categorical
project serial num
Project number (seems to be a grouping variable)
Categorical
award type
Type of award (1, 2, 3, 4, 4N, 5)
Categorical
activity code
Code for award
Categorical
award amount
Amount alloted for award
Quantitative
is active
Tells whether the award is ongoing or not (TRUE/FALSE)
Categorical
principal investigators
No values
NA
contact pi name
Names of PIs
Item
program officers
No values
NA
agency ic fundings
No values/unsure
NA
cong dist
Appears to be a subset of code for awards
Categorical
spending categories
No values
NA
project start date
Start date
Ordinal
project end date
End date
Ordinal
opportunity number
Appears to be a subset of code for awards
Categorical
award notice date
Date of notification of award
Ordinal
is new
Tells whether the award is new or not (TRUE/FALSE)
Categorical
mechanism code dc
Code for mechanism
Categorical
core project num
ID for award
Item
terms
Keywords grant proposes to address with award
Item
pref terms
Preferred keywords
Item
abstract text
Abstract
Item
project title
Title of project
Item
phr text
Some awards have project narrative text
Item
spending categories desc
Some awards have spending categories
Item
agency code
All = NIH
Categorical
covid response
No values/unsure
NA
arra funded
All = N
Categorical
budget start
Start date of budget
Ordinal
budget end
End date of budget
Ordinal
cfda code
Number assigned in the awarding document funded by the Federal government (similar to NSF)
Item
funding mechanism
Mechanism for funding (similar to DOE)
Categorical
direct cost amt
Cost directly of award
Quantitative
indirect cost amt
Cost indirectly of award
Quantitative
project detail url
Website of project details
Item
date added
Date award added
Ordinal
organization org name
Organization of awardee (either U of I or BSU)
Categorical
organization city
No values/unsure
NA
organization country
No values/unsure
NA
organization org city
City of University (either Moscow or Boise)
Categorical
organization org country
Country = USA
Categorical
organization org state
State = ID
Categorical
organization org state name
No values
NA
organization dept type
Department type being awarded (some have)
Categorical
organization fips country code
No values
NA
organization org duns
No values
NA
organization org ueis
No values
NA
organization primary duns
Seems to be some grouping variable
Categorical
organization primary uei
Seems to be some grouping variable
Categorical
organization org fips
All = US
Categorical
organization org ipf code
Seems to be some grouping variable
Categorical
organization org zipcode
Zipcode of organization
Categorical
organization external org id
Seems to be some grouping variable
Categorical
project num split appl type code
Seems to be values 1-10
Categorical
project num split activity code
Seems to be some grouping variable
Categorical
project num split ic code
Seems to be some grouping variable
Categorical
project num split serial num
Seems to be some grouping variable
Categorical
project num split support year
Not sure
Categorical
project num split full support year
Similar to previous
Categorical
project num split suffix code
Not sure (only some values have)
Categorical
agency ic admin code
Appears to be the same as project_num_split.ic_code
Categorical
agency ic admin abbreviation
Some sort of abbreviation
Categorical
agency ic admin name
Agency name (health related)
Categorical
organization type name
Type of organization
Categorical
organization type code
All = 10
Categorical
organization type is other
Extends organization type (TRUE/FALSE)
Categorical
full study section srg code
Seems to be some grouping variable
Categorical
full study section srg flex
Unsure (only some values have)
Categorical
full study section sra designator code
Some sort of grouping variable code
Categorical
full study section sra flex code
Unsure (some have letters, some numbers)
Categorical
full study section group code
Some sort of grouping code
Categorical
full study section name
Section name
Categorical
Figure 3: project_df Data Dictionary
Attribute
Description
Type
abstractText
Text of abstract
Item
agency
Agency awarding (for all = NSF)
Categorical
awardAgencyCode
All NSF codes appear to be 4900
Categorical
awardeeAddress
Address of awardee (all of these = U of I)
Item
awardeeCity
City of awardee
Item
awardeeCountryCode
Country of awardee
Item
awardeeDistrictCode
District code of awardee (all = ID01)
Categorical
awardeeName
Name of awardee (all = Regents of U of I)
Item
awardeeStateCode
State of awardee
Item
awardeeZipCode
Zip code of awardee
Item
cfdaNumber
Number assigned in the awarding document funded by the Federal government
Item
coPDPI
Unsure/no values
NA
ueiNumber
Code given to U of I awards (all are the same in this data set)
Item
estimatedTotalAmt
Estimated total amount of award
Quantitative
fundsObligatedAmt
Amount NSF is obligated to give
Quantitative
fundAgencyCode
Same code as above awardAgencyCode
Categorical
fundProgramName
Various program names
Item
id
Unique ID for each award
Item
parentUeiNumber
Unsure/no values
NA
pdPIName
Principle Investigator
Item
perfAddress
Preferred address of awardee (most are U of I, some elsewhere)
Item
perfCity
Preferred city
Item
perfCountryCode
Preferred country code
Item
perfDistrictCode
Preferred discrict code
Item
perfLocation
Preferred location (some prefer elsewhere- like Idaho Falls)
Item
perfStateCode
Preferred state code
Item
perfZipCode
Preferred zip code
Item
piEmail
Email of PI
Item
piFirstName
First name of PI
Item
piLastName
Last name of PI
Item
piMiddeInitial
Middle initial of PI
Item
poEmail
Email of Program Officer
Item
poName
Name of Program Officer
Item
poPhone
Phone of PO
Item
primaryProgram
Unsure/no values
NA
date
Current data?
Ordinal
startDate
Start date of award
Ordinal
expDate
End data of award
Ordinal
title
Title of award
Item
transType
Type of grant (continuing, standard, fellowship…)
Categorical
awardee
Again, here = regents of U of I for all
Item
publicationResearch
Unsure/no values
NA
projectOutComesReport
Some have a snippet on the findings thus far
Item
Figure 4: NSF to UI Data Dictionary
Source Code
---title: "BCB 520 - Midterm Portfolio Post"subtitle: "Evaluating Awards and Grants: UI vs. Others"author: "Heidi Sellmann"date: "2024-03-11"categories: [Assignment, DataViz, Tables, Project]image: "grants.jpg"code-fold: truecode-tools: truecode-link: truedescription: "Grants and awards and bears, oh my!"format: html: css: styles.csseditor: markdown: wrap: 72---```{r}knitr::opts_chunk$set(echo=FALSE, warning=FALSE, error=FALSE, message=FALSE)```# PREAMBLEIn this assignment I will be evaluating award/grant data from four federal sponsors: TheNational Science Foundation (NSF), The National Institutes of Health(NIH), The Department of Energy (DOE), and The US Department ofAgriculture (USDA).# DATA```{r Load libraries, warning = FALSE}library(httr)library(jsonlite)library(tidyverse)library(readxl)library(dplyr)library(ggplot2)```**1. Department of Agriculture (NIFA)** See the data dictionary here@fig-USDAtoUIDataDict. This includes agricultural related grants all theway from the early 2000s.```{r USDAtoUI, echo = FALSE}USDAtoUI<-read.csv("USDAtoUI.csv")# knitr::kable(head(USDAtoUI))```**2. Department of Energy (DOE)** The data dictionary for this extensive data set can be accessed here@fig-DOEDataDict. This data is not restricted to a particular awardrecipient.```{r DOE awards, message = FALSE, echo=FALSE}DOEawards<-read_excel("DOEawards.xlsx")#knitr::kable(head(DOEawards))```**3. National Institutes of Health (NIH)** This data can be obtainedfrom an Application Programming Interface (API). You can access this data's dictionary here @fig-project_dfDataDict. Thisis quite a large data set with information on awards (related to healthsciences) recieved by BSU and U of I between 2013-2024. Of note, this isan example of heirarchal data- some cells appear to have no values inthem becuase there are actually multiple variables within those cells.```{r NIH API}# Set the base URL for the APIbase_url <-"https://api.reporter.nih.gov/v2/projects/search"# This omits the `include_fields` option and downloads all the data for the University of Idaho and Boise State University from Fiscal Year 2013 to Fiscal Year 2024.# Build query parametersquery_params <-list(criteria =list(fiscal_years =2013:2024, # Specify range of fiscal yearsorg_names =list("UNIVERSITY OF IDAHO", "BOISE STATE UNIVERSITY")),offset =0, # Starting point for fetching results. Unlikely you'd ever want to change this.limit =500, # Maximum number of results to fetch. Sometimes the API sets a maximum. NIH does not.sort_field ="ProjectStartDate", # Field to sort by. Largely irrelevant as our visualizations should control this.sort_order ="desc"# Sort order)# Convert query parameters to JSON format. This part is tricky. This line converts the list above to a format (json) that the API will recognize. This is a place where Python is way better than R.query_json <-toJSON(query_params, auto_unbox =TRUE, null ="null", pretty =TRUE)# Set header information for the request. Some instructions to the API about our query.headers <-c("Content-Type"="application/json")# Send a POST request and retrieve response data. POST is just a type of API interaction. response is a json object. Click on it in your environment to see the hierarchical structure.response <-POST(base_url, body = query_json, encode ="json", httr::add_headers(.headers = headers))# Check if the request was successful. Sometimes the error is from our code. But sometimes it is from the API call. Status codes help us figure out where any problems might be.if (status_code(response) ==200) {# Extract and parse JSON data json_data_NIH <-content(response, as ="text", encoding ="UTF-8") parsed_data_NIH <-fromJSON(json_data_NIH, flatten =TRUE)# Select columns based on the actual JSON data structure. The data frame (technically the tibble) we want is in the results component. click on parsed_data and you'll see what I mean. projects_df <- parsed_data_NIH$results# Print the data frame. This is nice for debugging but you'll eventually want to stop doing this.# print(projects_df)# knitr::kable(head(projects_df))} else {# Print an error message if data fetching failedprint(paste("Failed to fetch data: Status code", status_code(response)))# Print the full response for debugging purposesprint(content(response, as ="text"))}```**4. National Science Foundation (NSF)** The NSF also has an API, andthe following code pulled down awards to the University of Idaho into adata frame called NSFtoUI. See the data dictionary here @fig-NSFtoUIDataDict. Briefly, this dataset gives information on NSF grants awarded to the University of Idahofrom 1975 to current day.```{r NSFtoUI load, eval = FALSE, message=FALSE}# Base URL for the APIbase_url <-"https://www.research.gov/awardapi-service/v1/awards.json?awardeeName=%22regents+of+the+university+of+idaho%22"printFields <-"rpp,offset,id,agency,awardeeCity,awardeeCountryCode,awardeeDistrictCode,awardeeName,awardeeStateCode,awardeeZipCode,cfdaNumber,coPDPI,date,startDate,expDate,estimatedTotalAmt,fundsObligatedAmt,ueiNumber,fundProgramName,parentUeiNumber,pdPIName,perfCity,perfCountryCode,perfDistrictCode,perfLocation,perfStateCode,perfZipCode,poName,primaryProgram,transType,title,awardee,poPhone,poEmail,awardeeAddress,perfAddress,publicationResearch,publicationConference,fundAgencyCode,awardAgencyCode,projectOutComesReport,abstractText,piFirstName,piMiddeInitial,piLastName,piEmail"# Initialize an empty data frame to store resultsNSFtoUI <-tibble()# Number of results per page (as per API settings)results_per_page <-25# Variable to keep track of the current page numbercurrent_page <-1# Variable to control the loopkeep_going <-TRUEwhile(keep_going) {# Calculate the offset for the current page offset <- (current_page -1) * results_per_page +1# Construct the full URL with offset url <-paste0(base_url, "&offset=", offset, "&printFields=", printFields)# Make the API call response <-GET(url)# Check if the call was successfulif (status_code(response) ==200) {# Extract and parse the JSON data json_data_NSF <-content(response, type ="text", encoding ="UTF-8") parsed_data_NSF <-fromJSON(json_data_NSF, flatten =TRUE)# Extract the 'award' data and add to the all_awards data frame awards_data <- parsed_data_NSF$response$award NSFtoUI <-bind_rows(NSFtoUI, as_tibble(awards_data))# Debug: Print the current page number and number of awards fetchedprint(paste("Page:", current_page, "- Awards fetched:", length(awards_data$id)))# Check if the current page has less than results_per_page awards, then it's the last pageif (length(awards_data$id) < results_per_page) { keep_going <-FALSE } else { current_page <- current_page +1 } } else {print(paste("Failed to fetch data: Status code", status_code(response))) keep_going <-FALSE }}``````{r Excel and NSFtoUI, warning=FALSE}library(writexl)# Write data frame to Excel file# write_xlsx(projects_df, "project_df")# write_xlsx(NSFtoUI, "NSFtoUI.xlsx")NSFtoUI <-read_excel("NSFtoUI.xlsx")#knitr::kable(head(NSFtoUI))```# QUESTION 1*Provide a visualization that shows our active awards from each sponsor.I need to see their start date and end date, the amount of the award,and the name of the Principal Investigator. I’m really interested inseeing how far into the future our current portfolio will exist. Arethere a bunch of awards about to expire? Are there a bunch that just gotfunded and will be active for a while? Does this vary across sponsors?*```{r Transforming DOE data}# Assuming your data is stored in a data frame called DOEawards# Convert 'Start Date' to date formatDOEawards$"Start Date"<-as.Date(DOEawards$"Start Date", format ="%m/%d/%Y")DOEawards$"End Date"<-as.Date(DOEawards$"End Date", format ="%m/%d/%Y")# Filter data for grants awarded to "Regents of the University of Idaho"DOEawards_df <- DOEawards %>%filter(Institution =="Regents of the University of Idaho")# Filter data for grants with an "Status" of "Active"DOEawards_df_active_grants <- DOEawards_df %>%filter(`Status`=="Active")# Remove dollar signs and convert "Amount Awarded to Date" to numeric formatDOEawards_df_active_grants$"Amount Awarded to Date"<-as.numeric(gsub("\\$", "", DOEawards_df_active_grants$"Amount Awarded to Date"))# Split PI column by comma and extract last namePI_last_name <-sapply(strsplit(as.character(DOEawards_df_active_grants$PI), ", "), function(x) x[1])# Create a new data frame with filtered and selected variables from DOEawards_df_active_grantsnewDOEawards <-data.frame(Start_Date = DOEawards_df_active_grants$"Start Date",End_Date = DOEawards_df_active_grants$"End Date",PI = DOEawards_df_active_grants$PI,PILastName = PI_last_name, # New column for last namePI_Grant =paste(PI_last_name, DOEawards_df_active_grants$"Register Number", sep =" "), # New column combining last name and Register NumberAmount_Awarded_to_Date = DOEawards_df_active_grants$"Amount Awarded to Date")# Create a new column named "Sponsor" with the desired valuesnewDOEawards <-mutate(newDOEawards, Sponsor ="DOE")# View the modified data set# head(newDOEawards)``````{r Trial graphing newDOEawards, eval=FALSE}# Example visualization using both Start Date and End Date on the x-axisggplot(data = newDOEawards, aes(x = Start_Date, xend = End_Date, y = PI, yend = PI, color = Amount_Awarded_to_Date)) +geom_segment(size =3) +labs(title ="DOE U of I Active Awards Amount Over Time by PI",x ="Time",y ="Principal Investigator",color ="Amount Awarded to Date") +theme(axis.text.x =element_text(angle =45, hjust =1)) +scale_x_date(date_labels ="%m-%Y", date_breaks ="6 months")``````{r Coloring by sponsors, eval = FALSE}# Example visualization using both Start Date and End Date on the x-axisggplot(data = newDOEawards, aes(x = Start_Date, xend = End_Date, y = PI, yend = PI, color = Sponsor)) +geom_segment(size =3) +geom_text(aes(x = End_Date, label = scales::dollar(Amount_Awarded_to_Date)), hjust =-0.1, vjust =0.5, size =3) +# Add labels for award amountslabs(title ="DOE U of I Active Awards Amount Over Time by PI",x ="Time",y ="Principal Investigator",color ="Sponsor") +theme(axis.text.x =element_text(angle =45, hjust =1)) +scale_x_date(date_labels ="%m-%Y", date_breaks ="6 months") +scale_color_discrete(name ="Sponsor") # Customize legend title```I am going to manipulate and make new data sets for allsponsors. Then I will combine them all and plot a summary figure.```{r Transforming NSF}# Assuming your data is stored in a data frame called NSFtoUI# Convert to date formatNSFtoUI$"startDate"<-as.Date(NSFtoUI$"startDate", format ="%m/%d/%Y")NSFtoUI$"expDate"<-as.Date(NSFtoUI$"expDate", format ="%m/%d/%Y")# Filter data for active grants # Filter data for grants with a "expDate" on or after 03/20/2024NSFtoUI_df_active_grants <- NSFtoUI %>%filter(`expDate`>=as.Date("2024-03-20")) # Create a new data frame with filtered and selected variables from NSFtoUI_df_active_grantsnewNSFtoUI <-data.frame(Start_Date = NSFtoUI_df_active_grants$"startDate",End_Date = NSFtoUI_df_active_grants$"expDate",PI = NSFtoUI_df_active_grants$"piLastName",PI_Grant =paste(NSFtoUI_df_active_grants$"piLastName", NSFtoUI_df_active_grants$id, sep =" "), # New column combining last name and idAmount_Awarded_to_Date = NSFtoUI_df_active_grants$"estimatedTotalAmt")# Create a new column named "Sponsor" with the desired valuesnewNSFtoUI <-mutate(newNSFtoUI, Sponsor ="NSF")# View the modified data set# head(newNSFtoUI)``````{r Transforming NIH data}# Assuming your data is stored in a data frame called projects_df# Assuming your data set is named projects_dfprojects_df$project_start_date <-as.Date(projects_df$project_start_date, format ="%Y-%m-%dT%H:%M:%SZ")projects_df$project_end_date <-as.Date(projects_df$project_end_date, format ="%Y-%m-%dT%H:%M:%SZ")# Filter data for grants awarded to "UNIVERSITY OF IDAHO"projects_df_df <- projects_df %>%filter(`organization.org_name`=="UNIVERSITY OF IDAHO")# Filter data for grants with an "is_active" of "TRUE"projects_df_active_grants <- projects_df_df %>%filter(`is_active`=="TRUE")# Create a new data frame with filtered and selected variables from projects_df_active_grantsnewNIH <- projects_df_active_grants %>%mutate(PI =str_to_title(contact_pi_name), # Convert contact_pi_name to sentence casePILastName1 =sapply(strsplit(as.character(PI), ", "), function(x) x[1]), # Extract last name from PI columnPI_Grant =paste(PILastName1, project_serial_num, sep =" ") # Combine PILastName1 and project_serial_num with a space ) %>%select(Start_Date = project_start_date,End_Date = project_end_date, PI, PI_Grant,Amount_Awarded_to_Date = direct_cost_amt )# Create a new column named "Sponsor" with the desired valuesnewNIH <-mutate(newNIH, Sponsor ="NIH")# Summarize the Amount_Awarded_to_Date for each unique PI_Grant while retaining other variablesnewNIH <- newNIH %>%group_by(PI_Grant) %>%mutate(Amount_Awarded_to_Date =sum(Amount_Awarded_to_Date, na.rm =TRUE)) %>%distinct(PI_Grant, .keep_all =TRUE) %>%ungroup()# View the modified data set# head(newNIH)``````{r Transforming USDA data}# Assuming your data is stored in a data frame called USDAtoUI# Assuming your data set is named USDAtoUIUSDAtoUI$"Award.Date"<-as.Date(as.character(USDAtoUI$"Award.Date"), format ="%m/%d/%Y")# Filter data for active grants # Filter data for grants with a "Award.Date" on or after 01/01/2019USDA_df_active_grants <- USDAtoUI %>%filter(`Award.Date`>=as.Date("2019-01-01")) # Create a new data frame with filtered and selected variables from USDA_df_active_grantsnewUSDAtoUI <-data.frame(Start_Date = USDA_df_active_grants$"Award.Date",End_Date = USDA_df_active_grants$"Award.Date",Amount_Awarded_to_Date = USDA_df_active_grants$"Award.Dollars")# Create a new column named "Sponsor" with the desired valuesnewUSDAtoUI <-mutate(newUSDAtoUI, Sponsor ="USDA")newUSDAtoUI <-mutate(newUSDAtoUI, PI ="NA")# View the modified data set# head(newUSDAtoUI)```## Putting all the active awards from various sponsors together```{r Visualizing new data frames from all sponsors, eval = FALSE}library(dplyr)# Convert Amount_Awarded_to_Date to numeric for the data set where it's stored as characternewNSFtoUI <- newNSFtoUI %>%mutate(Amount_Awarded_to_Date =as.numeric(Amount_Awarded_to_Date))# Bind the rows of the datasetscombined_active_grants_df <-bind_rows(mutate(newDOEawards, dataset ="DOE"),mutate(newNSFtoUI, dataset ="NSF"),mutate(newNIH, dataset ="NIH"))# Sort PI_Grant by Start_Datecombined_active_grants_df <- combined_active_grants_df %>%arrange(Start_Date) %>%mutate(PI_Grant =factor(PI_Grant, levels =unique(PI_Grant)) )# Define custom colors for each sponsorsponsor_colors <-c("DOE"="blue", "NIH"="green", "NSF"="red")# Filter the data to include only those with a start date from 2017 onwardscombined_active_grants_df_filtered <- combined_active_grants_df %>%filter(Start_Date >=as.Date("2017-01-01"))# Reorder PI_Grant by last name and start datecombined_active_grants_df_filtered <- combined_active_grants_df_filtered %>%mutate(Last_Name =sub("^(\\S+)\\s.*", "\\1", PI_Grant)) %>%arrange(Last_Name, desc(Start_Date)) %>%mutate(PI_Grant =factor(PI_Grant, levels =unique(PI_Grant)))# Plot the filtered dataquestion1plot_filtered <-ggplot(data = combined_active_grants_df_filtered, aes(x = Start_Date, xend = End_Date, y = PI_Grant)) +geom_segment(aes(yend = PI_Grant, color = Sponsor), size =2) +geom_text(aes(label = Amount_Awarded_to_Date, x = End_Date, y = PI_Grant), size =2.5, fontface ="bold", color ="black", hjust =-0.1) +# Changed hjust to position outside the barslabs(title ="U of I Active Awards Amount Over Time by PI (Since 2017)",x ="Time",y ="PI Grant",color ="Sponsor") +theme(axis.text.x =element_text(angle =90, hjust =1, size =6),axis.text.y =element_text(size =6),axis.title =element_text(size =9),legend.title =element_text(size =10),legend.text =element_text(size =9),plot.margin =margin(1, 1, 1, 1, "cm")) +scale_x_date(date_labels ="%m-%Y", date_breaks ="12 months") +scale_color_manual(name ="Sponsor", values = sponsor_colors)question1plot_filtered``````{r Save}# Convert Amount_Awarded_to_Date to numeric for the data set where it's stored as characternewNSFtoUI <- newNSFtoUI %>%mutate(Amount_Awarded_to_Date =as.numeric(Amount_Awarded_to_Date))# Bind the rows of the datasetscombined_active_grants_df <-bind_rows(mutate(newDOEawards, dataset ="DOE"),mutate(newNSFtoUI, dataset ="NSF"),mutate(newNIH, dataset ="NIH"))# Sort PI_Grant by Start_Datecombined_active_grants_df <- combined_active_grants_df %>%arrange(Start_Date) %>%mutate(PI_Grant =factor(PI_Grant, levels =unique(PI_Grant)) )# Define custom colors for each sponsorsponsor_colors <-c("DOE"="blue", "NIH"="green", "NSF"="red")# Filter the data to include only those with a start date from 2017 onwardscombined_active_grants_df_filtered <- combined_active_grants_df %>%filter(Start_Date >=as.Date("2017-01-01"))# Reorder PI_Grant by last name and start datecombined_active_grants_df_filtered <- combined_active_grants_df_filtered %>%mutate(Last_Name =sub("^(\\S+)\\s.*", "\\1", PI_Grant)) %>%arrange(Last_Name, desc(Start_Date)) %>%mutate(PI_Grant =factor(PI_Grant, levels =unique(PI_Grant)))# Plot the filtered dataquestion1plot_filtered <-ggplot(data = combined_active_grants_df_filtered, aes(x = Start_Date, xend = End_Date, y = PI_Grant)) +geom_segment(aes(yend = PI_Grant, color = Sponsor), size =2) +geom_text(aes(label = Amount_Awarded_to_Date, x = End_Date, y = PI_Grant), size =2.5, fontface ="bold", color ="black", hjust =-0.1) +# Changed hjust to position outside the barslabs(title ="U of I Active Awards Amount Over Time by PI (Since 2017)",x ="Time",y ="PI Grant",color ="Sponsor") +theme(axis.text.x =element_text(angle =90, hjust =1, size =6),axis.text.y =element_text(size =6),axis.title =element_text(size =9),legend.title =element_text(size =10),legend.text =element_text(size =9),plot.margin =margin(1, 1, 1, 1, "cm")) +scale_x_date(date_labels ="%m-%Y", date_breaks ="12 months") +scale_color_manual(name ="Sponsor", values = sponsor_colors)ggsave("question1plot.png", plot = question1plot_filtered, width =15, height =10)```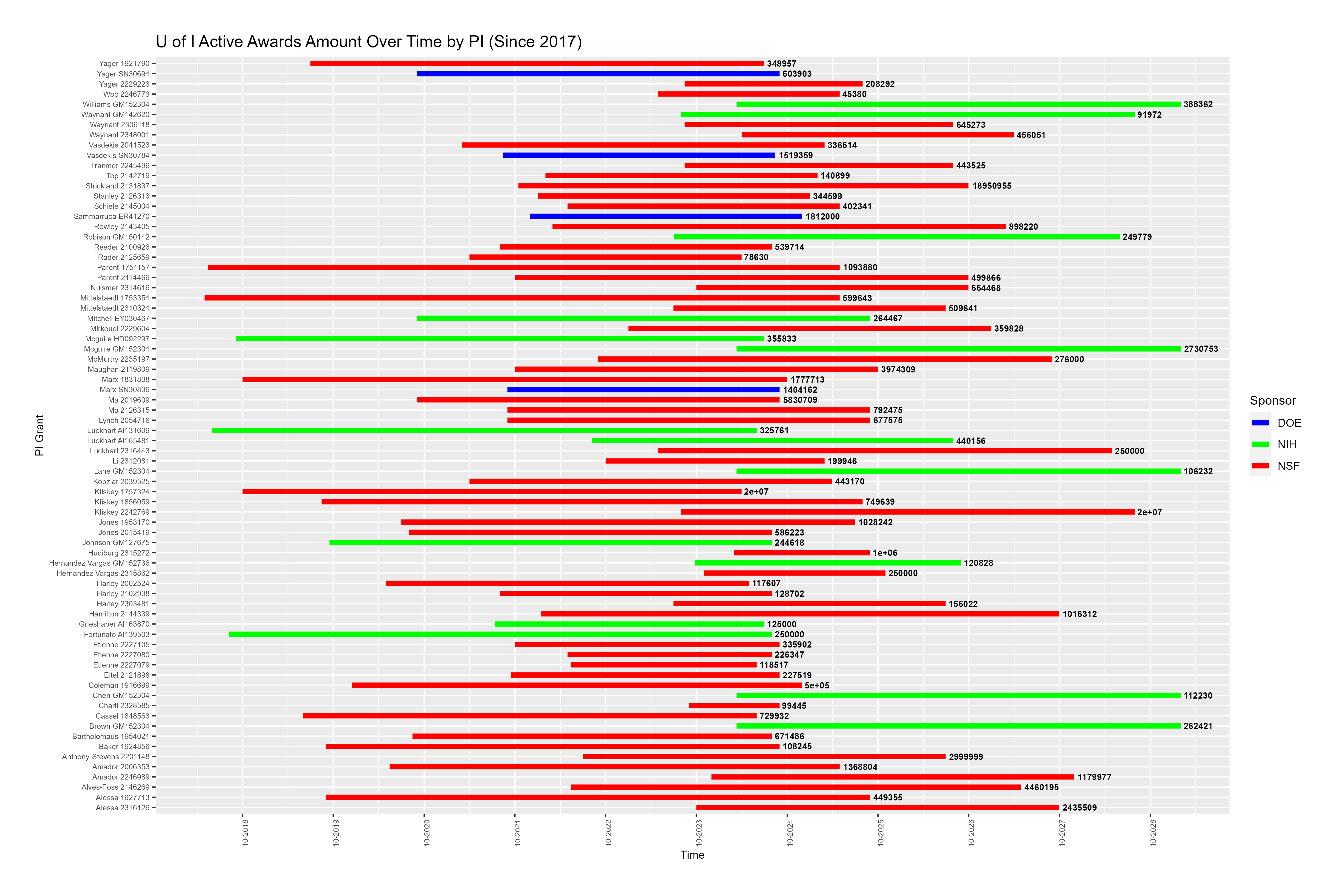**Figure 3.** This figure shows U of I PI last names and their active grants they have received as of 2017. The bars are colored by sponsor and the text amount signifies the amount they have received for said award. The USDA data is not included due to a lack of necessary variables. The strengths of this figure is that it displays, rather than over plots, PIs who have multiple awards. Limitations are that this figure only includes grants that have started in 2017 and on. # QUESTION 2*What is the proportional representation of new awards to the UI fromthese various sources over the past 5 to 10 years? Are there any trendsthat are encouraging or discouraging?*```{r DOE New Grant Counts}# Assuming your data is stored in a data frame called DOEawards# Convert 'Start Date' to date formatDOEawards$"Start Date"<-as.Date(DOEawards$"Start Date", format ="%m/%d/%Y")# Filter data for grants awarded to "Regents of the University of Idaho"DOEawards_df <- DOEawards %>%filter(Institution =="Regents of the University of Idaho")# Filter data for grants with an "Action Type" of "New"DOEawards_df_new_grants <- DOEawards_df %>%filter(`Action Type`=="New")# Filter data for grants with a "Start Date" on or after 01/01/2014DOEawards_df_new_grants <- DOEawards_df_new_grants %>%filter(`Start Date`>=as.Date("2014-01-01")) # Count the number of new grants for each yearnew_grants_count <- DOEawards_df_new_grants %>%group_by(Year = lubridate::year(`Start Date`)) %>%summarise(Count =n())``````{r Plot practice, eval = FALSE}# Plottingggplot(new_grants_count, aes(x = Year, y = Count)) +geom_bar(stat ="identity", fill ="skyblue") +labs(title ="Number of New DOE Grants to the University of Idaho (2014-Now)",x ="Year",y ="Number of New Grants") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1)) +scale_x_continuous(breaks =seq(min(new_grants_count$Year, na.rm =TRUE), max(new_grants_count$Year, na.rm =TRUE), by =1)) +geom_text(aes(label = Count), vjust =-0.3) +theme(axis.text =element_text(size =12),axis.title =element_text(size =14, face ="bold"),plot.title =element_text(size =16, face ="bold"))``````{r Finishing DOE new grants count}# Create a new column named "Sponsor" with the desired valuesDOE_new_grants_count <-mutate(new_grants_count, Sponsor ="DOE")# View the modified data set# head(DOE_new_grants_count)``````{r NSF New Grant Counts}# Assuming your data is stored in a data frame called NSFtoUI# Convert 'Date' to date formatNSFtoUI$"startDate"<-as.Date(NSFtoUI$"startDate", format ="%m/%d/%Y")# Filter data for grants awarded to "Regents of the University of Idaho"# Already are!# NSFtoUI_df <- NSFtoUI %>%# filter(Institution == "Regents of the University of Idaho")# Filter data for grants with an "transType" of "Standard Grant"NSFtoUI_df_new_grants <- NSFtoUI %>%filter(`transType`=="Standard Grant")# Filter data for grants with a "date" on or after 01/01/2014NSFtoUI_df_new_grants <- NSFtoUI_df_new_grants %>%filter(`startDate`>=as.Date("2014-01-01")) # Count the number of new grants for each yearNSF_new_grants_count <- NSFtoUI_df_new_grants %>%group_by(Year = lubridate::year(`startDate`)) %>%summarise(Count =n())# Finishing NSF new grants count with NSF column# Create a new column named "Sponsor" with the desired valuesNSF_new_grants_count <-mutate(NSF_new_grants_count, Sponsor ="NSF")# View the modified data set# head(NSF_new_grants_count)``````{r NIH New Grant Counts}# Assuming your data is stored in a data frame called projects_df# Assuming your data set is named projects_dfprojects_df$project_start_date <-as.Date(projects_df$project_start_date, format ="%Y-%m-%dT%H:%M:%SZ")# Filter data for grants awarded to "UNIVERSITY OF IDAHO"projects_df_df <- projects_df %>%filter(`organization.org_name`=="UNIVERSITY OF IDAHO")# Filter data for grants with an new grants# projects_df_new_grants <- projects_df_df %>%# filter(`is_new` == "TRUE")# I took this out becuase upon updating, the grants from 2024 considered "new" before were no longer considered "new".# Filter data for grants with a "project_start_date" on or after 01/01/2014projects_df_new_grants <- projects_df_df %>%filter(`project_start_date`>=as.Date("2014-01-01")) # Count the number of new grants for each yearprojects_df_new_grants_count <- projects_df_new_grants %>%group_by(Year = lubridate::year(`project_start_date`)) %>%summarise(Count =n())# Finishing NSF new grants count with NSF column# Create a new column named "Sponsor" with the desired valuesNIH_new_grants_count <-mutate(projects_df_new_grants_count, Sponsor ="NIH")# View the modified data set# head(NIH_new_grants_count)``````{r USDA New Grant Counts}# Assuming your data is stored in a data frame called USDAtoUIUSDAtoUI2<-read.csv("USDAtoUI.csv")# Assuming your data set is named USDAtoUIUSDAtoUI2$"Award.Date"<-as.Date(as.character(USDAtoUI2$"Award.Date"), format ="%m/%d/%Y")# Filter data for grants with a "Award.Date" on or after 01/01/2014USDA2_df_new_grants <- USDAtoUI2 %>%filter(`Award.Date`>=as.Date("2014-01-01")) # Count the number of new grants for each yearUSDA2_df_new_grants_count <- USDA2_df_new_grants %>%group_by(Year = lubridate::year(`Award.Date`)) %>%summarise(Count =n())# Finishing NSF new grants count with NSF column# Create a new column named "Sponsor" with the desired valuesUSDA2_new_grants_count <-mutate(USDA2_df_new_grants_count, Sponsor ="USDA")# View the modified dataset# head(USDA2_new_grants_count)```## Putting all the sponsors together```{r Visualizing all sponsors}# Combine data sets (assuming DOE_new_grants_count, NSF_new_grants_count, NIH_new_grants_count, and USDA_new_grants_count are your datasets)combined_grant_counts_df <-bind_rows(mutate(DOE_new_grants_count, dataset ="DOE"),mutate(NSF_new_grants_count, dataset ="NSF"),mutate(NIH_new_grants_count, dataset ="NIH"),mutate(USDA2_new_grants_count, dataset ="USDA"))# Plottingggplot(combined_grant_counts_df, aes(x = Year, y = Count, color = dataset)) +geom_line() +# geom_point(data = filter(combined_grant_counts_df, Sponsor == "NIH"), color = "green", size = 3) + # Add points for Dataset 3- no longer need upon updatinglabs(title ="Trends Across Multiple Datasets During the Last Decade",x ="Year",y ="Count") +theme_minimal() +theme(axis.text.x =element_text(angle =45, hjust =1)) +scale_x_continuous(breaks =seq(min(combined_grant_counts_df$Year, na.rm =TRUE), max(combined_grant_counts_df$Year, na.rm =TRUE), by =1)) +scale_color_manual(values =c("DOE"="blue", "NSF"="red", "NIH"="green", "USDA"="orange")) +theme(axis.text =element_text(size =12),axis.title =element_text(size =14, face ="bold"),plot.title =element_text(size =16, face ="bold"))```**Figure 5.** This figure shows the approximate trends of new grants received by theUniversity of Idaho from various sponsors in the last 10 years.Limitations include that the USDA data set did not have specificationsdenoting whether the awards were new or continuing, therefore, I wasonly able to go off the award date for being in the last 10 years andhad to make the assumption all were new. This is most likely not thecase, so the orange line should be interpreted with caution. In general,the USDA actually seems to be on the decline, which would be concerninggiven the type of school the University of Idaho is. As for the DOE, itseems we are on the rise during the past couple years. The NSF seems tobe steady at the moment. Meanwhile, the NIH data was interesting. Upon updating this document, grants considered "new" a week previously were not considered "new" anymore. Therefore, I just included all grants from the past 10 years. All in all, this is an interesting figure to address general trends within the last decade. # QUESTION 3*How is UI performing with these sponsors when compared to the followingpeer institutions: Boise State University,* *Idaho State University,**Montana State University,* *University of Montana, and* *WashingtonState University?**Note that “performing” can mean a variety of different things. You mustchoose your metrics of performance and justify them.*I am going to use the API sources forthis question (NIH and NSF) by manipulating the API addresses and then manipulating the data. ```{r NIH5 API}# Set the base URL for the APIbase_url <-"https://api.reporter.nih.gov/v2/projects/search"# This omits the `include_fields` option and downloads all the data for the University of Idaho and Boise State University from Fiscal Year 2013 to Fiscal Year 2024.# Build query parametersquery_params <-list(criteria =list(fiscal_years =2013:2024, # Specify range of fiscal yearsorg_names =list("UNIVERSITY OF IDAHO", "BOISE STATE UNIVERSITY", "IDAHO STATE UNIVERSITY", "MONTANA STATE UNIVERSITY", "UNIVERSITY OF MONTANA", "WASHINGTON STATE UNIVERSITY")),offset =0, # Starting point for fetching results. Unlikely you'd ever want to change this.limit =500, # Maximum number of results to fetch. Sometimes the API sets a maximum. NIH does not.sort_field ="ProjectStartDate", # Field to sort by. Largely irrelevant as our visualizations should control this.sort_order ="desc"# Sort order)# Convert query parameters to JSON format. This part is tricky. This line converts the list above to a format (json) that the API will recognize. This is a place where Python is way better than R.query_json <-toJSON(query_params, auto_unbox =TRUE, null ="null", pretty =TRUE)# Set header information for the request. Some instructions to the API about our query.headers <-c("Content-Type"="application/json")# Send a POST request and retrieve response data. POST is just a type of API interaction. response is a json object. Click on it in your environment to see the hierarchical structure.response <-POST(base_url, body = query_json, encode ="json", httr::add_headers(.headers = headers))# Check if the request was successful. Sometimes the error is from our code. But sometimes it is from the API call. Status codes help us figure out where any problems might be.if (status_code(response) ==200) {# Extract and parse JSON data json_data_NIH5 <-content(response, as ="text", encoding ="UTF-8") parsed_data_NIH5 <-fromJSON(json_data_NIH5, flatten =TRUE)# Select columns based on the actual JSON data structure. The data frame (technically the tibble) we want is in the results component. click on parsed_data and you'll see what I mean. projects_df5 <- parsed_data_NIH5$results# Print the data frame. This is nice for debugging but you'll eventually want to stop doing this.#print(projects_df5)# knitr::kable(head(projects_df5))} else {# Print an error message if data fetching failedprint(paste("Failed to fetch data: Status code", status_code(response)))# Print the full response for debugging purposesprint(content(response, as ="text"))}``````{r NSF5, eval = FALSE, message=FALSE}# Base URL for the API with multiple awardeesbase_url <-"https://www.research.gov/awardapi-service/v1/awards.json?awardeeName=%22regents+of+the+university+of+idaho%22%20OR%20%22boise+state+university%22%20OR%20%22idaho+state+university%22%20OR%20%22montana+state+university%22%20OR%20%22university+of+montana%22%20OR%20%22washington+state+university%22"printFields <-"rpp,offset,id,agency,awardeeCity,awardeeCountryCode,awardeeDistrictCode,awardeeName,awardeeStateCode,awardeeZipCode,cfdaNumber,coPDPI,date,startDate,expDate,estimatedTotalAmt,fundsObligatedAmt,ueiNumber,fundProgramName,parentUeiNumber,pdPIName,perfCity,perfCountryCode,perfDistrictCode,perfLocation,perfStateCode,perfZipCode,poName,primaryProgram,transType,title,awardee,poPhone,poEmail,awardeeAddress,perfAddress,publicationResearch,publicationConference,fundAgencyCode,awardAgencyCode,projectOutComesReport,abstractText,piFirstName,piMiddeInitial,piLastName,piEmail"# Initialize an empty data frame to store resultsNSF5 <-tibble()# Number of results per page (as per API settings)results_per_page <-25# Variable to keep track of the current page numbercurrent_page <-1# Variable to control the loopkeep_going <-TRUEwhile(keep_going) {# Calculate the offset for the current page offset <- (current_page -1) * results_per_page +1# Construct the full URL with offset url <-paste0(base_url, "&offset=", offset, "&printFields=", printFields)# Make the API call response <-GET(url)# Check if the call was successfulif (status_code(response) ==200) {# Extract and parse the JSON data json_data_NSF5 <-content(response, type ="text", encoding ="UTF-8") parsed_data_NSF5 <-fromJSON(json_data_NSF5, flatten =TRUE)# Extract the 'award' data and add to the all_awards data frame awards_data <- parsed_data_NSF5$response$award NSF5 <-bind_rows(NSF5, as_tibble(awards_data))# Debug: Print the current page number and number of awards fetchedprint(paste("Page:", current_page, "- Awards fetched:", length(awards_data$id)))# Check if the current page has less than results_per_page awards, then it's the last pageif (length(awards_data$id) < results_per_page) { keep_going <-FALSE } else { current_page <- current_page +1 } } else {print(paste("Failed to fetch data: Status code", status_code(response))) keep_going <-FALSE }}``````{r Excel for NSF5 and NIH5, warning=FALSE}library(writexl)# Write data frame to Excel file#write_xlsx(projects_df5, "project_df5")#write_xlsx(NSF5, "NSF5.xlsx")NSF5 <-read_excel("NSF5.xlsx")#knitr::kable(head(NSFtoUI))``````{r Transforming NSF5}# Assuming your data is stored in a data frame called NSF5# Convert to date formatNSF5$"expDate"<-as.Date(NSF5$"expDate", format ="%m/%d/%Y")# Filter data for active grants # Filter data for grants with a "expDate" on or after 03/20/2024NSF5_df_active_grants <- NSF5 %>%filter(`expDate`>=as.Date("2024-03-20")) # Create a new data frame with filtered and selected variables from NSF5_df_active_grantsnewNSF5 <-data.frame(Organization = NSF5_df_active_grants$"awardeeName",Amount_Awarded = NSF5_df_active_grants$"estimatedTotalAmt")# Create a new column named "Sponsor" with the desired valuesnewNSF5 <-mutate(newNSF5, Sponsor ="NSF")# View the modified data set# head(newNSF5)``````{r Transforming NIH5 data}# Assuming your data is stored in a dataframe called projects_df5# Filter data for grants with an "is_active" of "TRUE"projects_df5_active_grants <- projects_df5 %>%filter(`is_active`=="TRUE")# Add a new column called estimated_cost_amt containing the sum of direct_cost_amt and indirect_cost_amtprojects_df5_active_grants$estimated_cost_amt <-rowSums(projects_df5_active_grants[, c("direct_cost_amt", "indirect_cost_amt")])# Create a new data frame with filtered and selected variables from projects_df5_active_grantsnewNIH5 <-data.frame(Organization = projects_df5_active_grants$"organization.org_name",Amount_Awarded = projects_df5_active_grants$"estimated_cost_amt")# Create a new column named "Sponsor" with the desired valuesnewNIH5 <-mutate(newNIH5, Sponsor ="NIH")# View the modified data set# head(newNIH5)```## Combining NIH and NSF for neighboring schools```{r Visualizing all the schools from NIH and NSF, warning=FALSE}# Convert Amount_Awarded_to_Date to numeric for the data set where it's stored as characternewNSF5 <- newNSF5 %>%mutate(Amount_Awarded =as.numeric(Amount_Awarded))combined_all_schools_active_grants_df <-bind_rows(mutate(newNSF5, dataset ="NSF"),mutate(newNIH5, dataset ="NIH")) # Create a ggplot objectggplot(combined_all_schools_active_grants_df, aes(x = Organization, y = Amount_Awarded, fill = Sponsor)) +geom_bar(stat ="identity", position ="stack") +labs(title ="Bar Chart of Award Amounts by Sponsor and Organization",x ="Organization",y ="Amount Awarded",fill ="Sponsor") +theme_minimal() +theme(legend.position ="top",axis.text.x =element_text(angle =90, vjust =0.5, hjust=1))```**Figure 6.** This figure shows the award amounts of the active grants of eachinstitution (and their various locations) sponsored by the NIH (coral)and NSF (blue).I used the measures of active awards and their relative amounts fromthese sponsors to address how the U of I compares to neighboringinstitutions. Although not complex, these performance attributes captureimportant metrics nonetheless.The limitations of this figure are first and foremost that it onlyaddresses grants from the NIH and NSF, not the USDA and DOE. I chose todo this out of sake for convenience. Also, for the NIH, this time Iadded the indirect and direct costs to compute the award amount (inFigure 1., I only used direct cost). Further, because of the discrepantdata sources, some of the institutions have multiple locations alsoshown in this figure. Although I could agglomerate the data so eachinstitution has one reference point, I actually think this may beinsightful to see how the smaller institutions compare to the largerones. In general, I could clean this figure up to look a little nicer. All in all, from this figure, we can see the U of I compares well in therealm of NSF grants. This is not so much the case for the NIH grants.# SUMMARYIn conclusion, this stuff is messy indeed! Throughout my three mainvisualizations, I found out what active grants the U of I has and howthose compare across sponsors. I then expanded that information tocompare specific sponsors to various other schools nearby. In general,we need more DOE and NIH work to be done. USDA and NSF are doing well,but we want to get back on the rise again (at least with the USDA).I realized through this work that, as Barrie has alluded to, it indeeddoes take a lot of time going through these different data and findingwhat is similar/comparable and cleaning those aspects of the data inorder to put visualizations together. Further, I learned the hard way that **LESS IS MORE!** I think it would be interesting to continue to explore and see how the Uof I compares to other institutions with the other sponsors, and Iwonder how data scientists wrap their heads around all these details!# APPENDIX## Data Dictionary```{r Load data dictionary, warning=FALSE}# Read a specific sheet from the Excel filelibrary(readxl)AwardsDictionary <-read_excel("AwardsDictionary.xlsx")``````{r, warning = FALSE}#| label: fig-USDAtoUIDataDict#| fig-cap: "USDAtoUI Data Dictionary"AwardsDictionaryUSDAtoUI <-read_excel("AwardsDictionary.xlsx", sheet ="USDAtoUI")knitr::kable(AwardsDictionaryUSDAtoUI)``````{r, warning = FALSE}#| label: fig-DOEDataDict#| fig-cap: "DOE Data Dictionary"AwardsDictionaryDOE <-read_excel("AwardsDictionary.xlsx", sheet ="DOE")knitr::kable(AwardsDictionaryDOE)``````{r}#| label: fig-project_dfDataDict#| fig-cap: "project_df Data Dictionary"AwardsDictionaryproject_df <-read_excel("AwardsDictionary.xlsx", sheet ="project_df")knitr::kable(AwardsDictionaryproject_df)``````{r}#| label: fig-NSFtoUIDataDict#| fig-cap: "NSF to UI Data Dictionary"AwardsDictionaryNSFtoUI <-read_excel("AwardsDictionary.xlsx", sheet ="NSFtoUI")knitr::kable(AwardsDictionaryNSFtoUI)```


